AI 연구개발 기업 딥시크(DeepSeek)가 새로운 멀티모달 AI 모델 DeepSeek-OCR을 공개했다. OCR(Optical Character Recognition)은 스캔된 문서 등에서 텍스트를 인식하는 기술로 이번 모델은 토큰 수를 대폭 줄이면서도 대규모이자 복잡한 문서를 처리할 수 있는 게 특징이다.
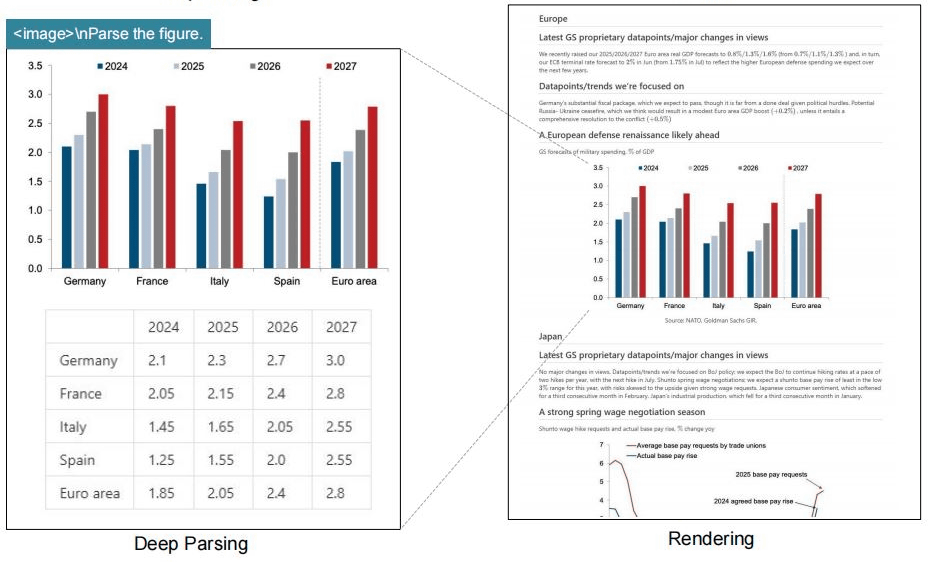
DeepSeek-OCR은 이름 그대로 OCR 처리를 위해 특화된 6.6GB 규모 AI 모델로 원본 정보 97%를 유지하면서 텍스트 데이터를 10분의 1로 압축할 수 있다. 시스템은 2가지 핵심 구성 요소로 이뤄져 있으며 3억 8,000만 개 파라미터를 가진 이미지 처리용 DeepEncoder와 5억 7,000만 개 활성 파라미터를 지닌 DeepSeek3B-MoE 기반 텍스트 생성기로 구성된다.
DeepEncoder 내부에서는 이미지 인식 결과를 CLIP 모델로 전달하는 과정에서 토큰을 줄이고 이미지와 텍스트를 연결하는 작업이 수행된다. 1024×1024픽셀 이미지는 원래 4,096개 토큰으로 처리되지만 DeepEncoder의 압축 과정을 거치면 256토큰으로 축소된다.
DeepSeek-OCR은 다양한 해상도 이미지에서 동작할 수 있으며 필요한 비전 토큰 수는 저해상도 이미지의 경우 64개, 고해상도에서는 최대 400개에 불과하다. 같은 작업을 기존 OCR 시스템이 처리할 경우 수천 개에 이르는 토큰이 필요하다.
성능 면에서 DeepSeek-OCR은 NVIDIA A100 GPU 1대로 하루 20만 페이지 이상을 처리할 수 있다. A100 GPU 8대를 탑재한 서버 20대 규모 환경에서는 하루 3,300만 페이지 처리가 가능하다.
보도에선 DeepSeek-OCR 도입으로 사용자가 확장 가능한 초장문 컨텍스트 처리를 수행할 수 있게 됐다고 평가했다. 이 시스템은 최근 컨텍스트를 고해상도로 유지하면서 오래된 컨텍스트는 더 적은 연산 자원으로 처리해 정보 유지와 효율성 간의 균형을 잡는다. 이런 접근이 이론상 무제한 컨텍스트 아키텍처로 나아가는 길을 열었다는 분석이다. 관련 내용은 이곳에서 확인할 수 있다.
![[AI서머리] 대구 C-Lab 17기, 데모데이로 성과 공개‧디캠프, ‘스타트업OI #CVC’ 행사 개최](https://startuprecipe.co.kr/wp-content/uploads/2025/10/251024_IPX_000235-75x75.jpg)
















{kind=link}