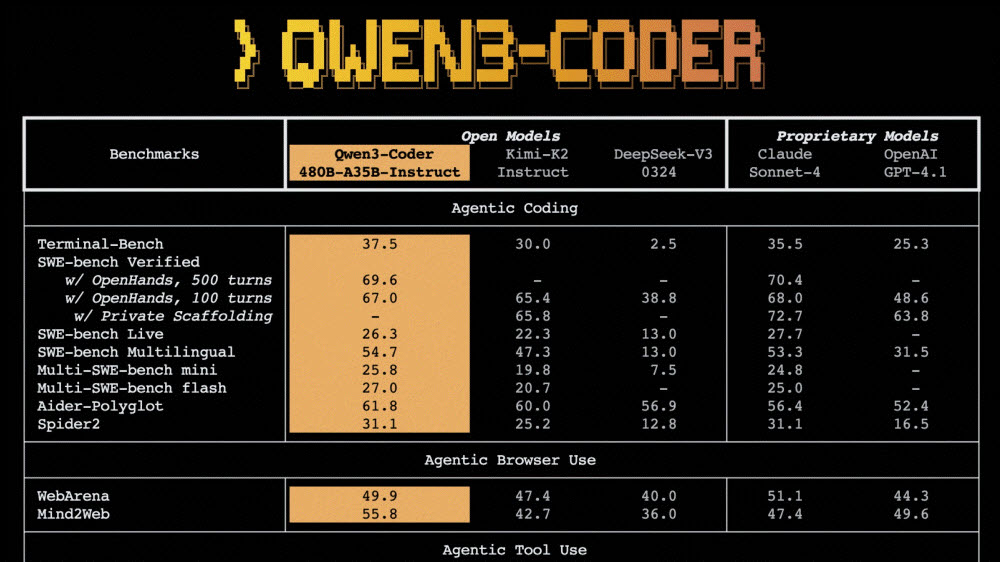
알리바바 대규모 언어모델 Qwen 연구팀이 코딩에 특화된 에이전트 모델인 Qwen3-Coder를 발표했다. 파라미터 수 4.800억 개, 액티브 파라미터 수 350억 개 모델 Qwen3-Coder-480B-A35B-Instruct는 클로드 소넷4(Claude Sonnet 4)에 필적하는 결과를 달성했다.
Qwen3-Coder가 갖춘 가장 큰 특징은 네이티브로 256K 토큰이라는 광대한 컨텍스트 길이를 지원할 뿐 아니라 YaRN(Yet another RoPE-based scaling method)이라는 확장 기술을 사용해 100만 토큰까지 대응 가능하다는 점. 이를 통해 리포지토리 전체를 이해하는 대규모 태스크에도 대응할 수 있다. 또 C++, 자바, 파이썬, 루비, 스위프트, ABAP 등을 포함한 358개에 이르는 다양한 프로그래밍 언어를 지원한다. 더불어 베이스 모델로부터 일반적인 능력과 수학적 능력을 유지하면서 코딩에 특화되어 있다.
또 해당 능력을 최대한 끌어내기 위해 에이전트 코딩용 커맨드라인 도구인 Qwen Code도 동시에 오픈소스화됐다. Qwen Code는 제미나이 코드(Gemini Code)를 포크해 개발됐다.
알리바바 측은 성능 면에서 Qwen3-Coder는 오픈소스 모델 중에서 에이전트 코딩, 에이전트 브라우저 조작, 에이전트 도구 사용 분야에서 새로운 최고 수준 기록을 수립했다고 강조했다. Qwen3-Coder는 소프트웨어 엔지니어링 태스크 평가(SWE-Bench Verified)에서 클로드 소넷4보다 작은 모델 크기로 거의 동등한 점수를 기록했다.
알리바바에 따르면 사전 학습 단계에서는 7조 5,000억 토큰이라는 방대한 데이터가 사용됐으며 70%가 코드로 구성되어 있다. 또 Qwen2.5-Coder를 활용해 노이즈가 많은 데이터를 정리하고 다시 작성해 데이터 전체 품질을 대폭 향상시켰다.
후속 학습에서는 2가지 중요한 강화학습(RL)이 대규모로 도입됐다. 먼저 다양한 실세계 코딩 태스크에 대해 코드 강화학습(Code RL)을 적용해 코드 실행 성공률을 대폭 향상시켰다. 더불어 SWE-Bench 같은 다중 턴 대화가 필요한 태스크에 대응하기 위해 장기적 관점 강화학습이 도입됐다. 이 구현에는 알리바바 클라우드 인프라가 활용됐으며 2만 종류 독립 환경을 병렬로 실행할 수 있는 확장성 높은 시스템이 구축됐다.
Qwen3-Coder는 여러 모델이 있지만 지금은 Qwen3-Coder-480B-A35B-Instruct가 허깅페이스와 모델스코프에서 이용 가능하다. 또 추론 효율화에 기여하는 FP8로 양자화된 모델 Qwen3-Coder-480B-A35B-Instruct-FP8도 허깅페이스와 모델스코프에서 제공되고 있다. 더불어 알리바바 클라우드 모델 스튜디오를 통해 Qwen3-Coder의 API에 직접 접근할 수 있다. 관련 내용은 이곳에서 확인할 수 있다.
![[AI서머리] 한성숙 중기부 장관 “회복과 성장의 새 출발”‧’성남 판교 High R&D 스타트업 육성 협의체’ 출범](https://startuprecipe.co.kr/wp-content/uploads/2025/07/250724_gangwon_600346-75x75.jpg)
![[AI서머리] 스타트업 월드컵 코리아-경산 참가기업 모집‧오아세스, 관광벤처사업 선정](https://startuprecipe.co.kr/wp-content/uploads/2026/04/260429_SBVA_5032005235-350x250.jpeg)
















{kind=link}