애플이 자사 시각언어 모델(Vision Language Model, VLM)인 FastVLM을 공식 발표했다. 기존 VLM은 정밀도를 높이면 효율성이 떨어지는 문제가 있었지만 FastVLM은 높은 정밀도를 유지하면서도 효율적인 성능을 구현해 온디바이스에서 실시간으로 비주얼 쿼리를 처리하는 데 적합한 모델이라고 한다.
VLM은 텍스트 입력 외에도 시각적 이해를 가능하게 하는 AI 모델이다. 보통 사전 학습된 비전 인코더에서 투영 계층을 거쳐 사전 학습된 대규모 언어 모델(LLM)로 시각 토큰을 전달하는 방식으로 구성된다. 풍부한 비전 인코더 시각 표현과 LLM이 갖춘 세계 지식 및 추론 기능을 결합해 접근성 도우미, UI 내비게이션, 로보틱스, 게임 등 다양한 애플리케이션에 활용할 수 있다.
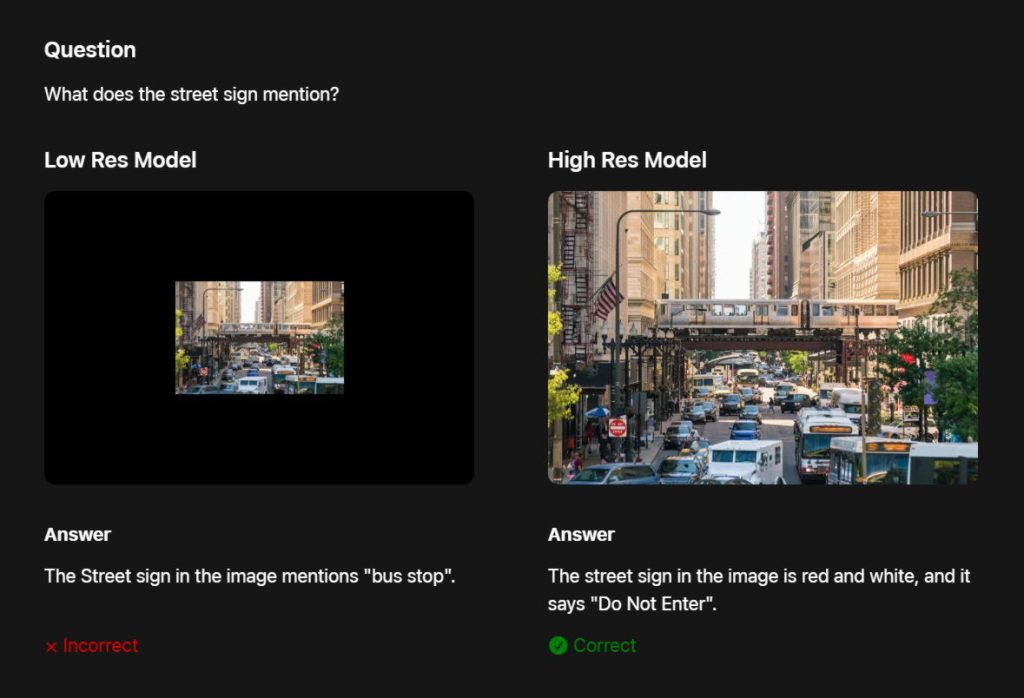
VLM 정밀도는 보통 입력 이미지 해상도가 높을수록 향상되기 때문에 정밀도와 효율성 사이에 트레이드오프가 존재한다. 그 중에서도 문서 분석, UI 인식, 이미지 기반 자연어 쿼리 응답 등 정밀한 이해가 요구되는 작업에서 이 문제가 두드러진다. 예를 들어 이미지 속 교통 표지판에 대한 질문을 했을 때 저해상도 이미지로는 정확한 응답이 어렵지만 고해상도 이미지라면 표지판을 정확히 식별할 수 있다.
하지만 실사용 사례 다수는 실시간 애플리케이션에서 낮은 지연 시간을 요구하고 프라이버시 보호를 위해 AI를 온디바이스에서 실행해야 한다. 따라서 VLM은 높은 정밀도와 효율성을 동시에 갖춰야 한다.
문제는 고해상도 이미지가 VLM 지연 시간을 크게 늘려, 효율성을 심각하게 저하시킨다는 점이다. 이유는 2가지로 나뉜다. 첫째는 고해상도 이미지일수록 비전 인코더 처리 시간이 길어진다는 점, 둘째는 인코더가 더 많은 시각 토큰을 생성하면서 LLM 사전 입력 시간이 길어지기 때문이다. 이로 인해 비전 인코딩 시간과 LLM 사전 입력 시간 합인 첫 토큰 생성까지의 시간(TTFT)이 증가하게 된다.
애플 머신러닝 연구진은 이러한 VLM 한계를 극복하기 위해 독자 방식으로 설계한 FastVLM을 선보였다. 이 모델은 단순한 구조지만 정밀도와 지연 시간 간 트레이드오프를 크게 개선했다. 고해상도 이미지 처리를 위해 설계된 하이브리드 아키텍처의 비전 인코더를 활용하며 정확하고 빠르며 효율적인 비주얼 쿼리 처리를 구현했다. 또 온디바이스에서 동작하는 실시간 애플리케이션 개발에도 적합하다고 한다.
애플은 어떤 아키텍처가 높은 정밀도-지연 시간 트레이드오프를 제공하는지를 확인하기 위해 학습 데이터, 알고리즘, LLM은 동일하게 유지한 채 비전 인코더만을 변경해 체계적인 비교 실험을 진행했다. 실험 대상은 FastViT, ViT-L/14, SigLIP-SO400, ConvNeXT 등이다. 그 결과 FastViT가 다른 VLM보다 정밀도와 지연 시간 모두에서 최적의 균형을 보여주는 것으로 나타났다.
FastViT는 효율적인 VLM 구현에 최적화된 선택지지만 복잡한 작업에서의 정밀도를 높이려면 더 큰 규모 비전 인코더가 필요하다. 애플은 처음에는 FastViT 각 레이어 크기를 단순히 키우는 방식으로 대응하려 했지만 이 경우 고해상도 이미지에서는 완전한 컨볼루션 인코더보다 효율이 떨어졌다.
이에 애플은 고해상도 이미지 전용 백본인 FastViTHD를 새롭게 설계했다. FastViTHD는 FastViT보다 추가 스테이지를 포함하고 있으며 MobileCLIP을 활용한 사전 학습을 통해 더 적은 수로 고품질 시각 토큰을 생성할 수 있다.
FastViTHD는 고해상도 이미지에서 FastViT보다 뛰어난 레이턴시를 보여주며 다양한 크기 LLM과 조합해 성능을 비교한 결과 동일한 정밀도에서 최대 3배 빠르게 작동할 수 있다는 게 입증됐다.
FastVLM은 FastViTHD를 비전 인코더로 사용하고 생성된 시각 토큰을 LLM 임베딩 공간에 투영하는 단순한 다층 퍼셉트론(MLP) 모듈을 갖춘 구조로 구성된다.
FastVLM은 고해상도 이미지를 빠르게 처리하기 위해 이미지를 여러 조각으로 분할하고 각 조각을 비전 인코더로 개별 처리한 뒤 모든 토큰을 LLM에 전달하는 방식을 채택하고 있다. 이 접근 방식 덕분에 FastVLM은 동급의 다른 VLM보다 빠르고 정확한 성능을 보인다.
VLM은 시각적 이해와 텍스트 이해를 결합해 다양한 응용 가능성을 지닌 기술이다. 하지만 정밀도가 입력 이미지 해상도에 민감하게 반응하고 이로 인해 성능 효율성과의 충돌이 자주 발생해 두 조건을 동시에 만족시켜야 하는 실사용 환경에서는 활용이 제한적이었다.
FastVLM은 고해상도 이미지에 특화된 하이브리드 아키텍처 FastViTHD를 기반으로 해 이 같은 문제를 해결했다. 단순한 설계임에도 불구하고 FastVLM은 기존 방식보다 높은 정밀도와 효율성을 동시에 제공하며 온디바이스 실시간 애플리케이션에 적합한 비주얼 쿼리 처리를 실현할 수 있다는 설명이다.
한편 애플은 MLX를 기반으로 한 추론 코드와 모델 체크포인트, iOS 및 맥OS용 데모 애플리케이션 코드를 깃허브에 공개했다. 관련 내용은 이곳에서 확인할 수 있다.
![[AI서머리] 경기창경, AI·빅데이터 분야 스타트업 IR 개최‧어른이 보호구역, 여름 감성 전시 개막](https://startuprecipe.co.kr/wp-content/uploads/2025/07/250725_Gyeonggi-Center-for-Creative-Economy-Innovation_600346-75x75.jpg)

















{kind=link}